
PAPER TO HTML: A PUBLICLY AVAILABLE WEB TOOL FOR CONVERTING SCIENTIFIC PDFS INTO ACCESSIBLE HTML
Lucy Lu Wang, University of Washington, Allen Institute for AI, Seattle, WA, USA, lucylw@uw.edu
Jonathan Bragg, Allen Institute for AI, Seattle, WA, USA, jbragg@allenai.org
Daniel S. Weld, University of Washington, Allen Institute for AI, Seattle, WA, USA, danw@allenai.org
Most scientific papers are distributed in PDF format, which is by default inaccessible to blind and low vision audiences and people who use assistive reading technology. These access barriers hinder and may even deter members of these groups from pursuing careers or opportunities that necessitate the reading of technical documents. In cases where no accessible versions of papers are made available by publishers or authors, the gold standard for PDF document accessibility is PDF remediation. Remediation is the process by which a PDF is made accessible by fixing accessibility errors, for example, tagging headings, specifying reading order, adding alt text to images, and so on, such that a reader can navigate and engage with the resulting content using assistive reading technology such as screen readers.
In many academic and research settings, access to paper remediation services is limited or incurs long wait times, e.g., it is not atypical for requesters to wait several weeks for fulfillment at many universities. For others not affiliated with well-resourced institutions, remediation services may not be available at all. Though there are semi-automated remediation tools in software such as Adobe Acrobat Pro, the process requires significant manual effort and iteration, and must be done from scratch for each new PDF (Bigham et al. 2016). It is also difficult to validate that all accessibility errors have been fixed, since accessibility checking tools are imperfect and it is impractical to verify the accuracy on all words, headings, and other components by hand.
We investigated accessibility challenges with reading scientific documents and whether AI technologies could help to mitigate them (Wang et al. 2021a). Incorporating findings from our study, we created and deployed a reading tool called Paper to HTML (https://papertohtml.org/), a web application where users can upload and convert page-locked scientific paper PDFs to HTML documents on demand (Wang et al. 2021b). We presented an early prototype of this system, which was called SciA11y, at the 2021 ACM SIGACCESS Conference on Computers and Accessibility (ASSETS), where it won the Best Artifact Award.
Paper to HTML uses machine learning models specialized for scientific documents to extract the text and visual content from PDFs. The system infers headings and proper reading order, producing a more accessible HTML version of the document as output. In our study, we determined that automated conversion into HTML is currently not perfectly faithful to the source PDF document. However, given fairly accurate outputs and immediate access, most participants in our user study found this to be a reasonable tradeoff, stating that they would use the tool in the future. Additionally, beyond fully automated conversion, we also believe that the technologies developed for Paper to HTML have the potential to reduce efforts for current remediation processes, for example, by providing higher-quality extractions that require fewer corrections. In which case, we may be able to involve remediation experts in the loop to provide accessible documents with both better accuracy and timeliness.
Improvements and next steps for Paper to HTML
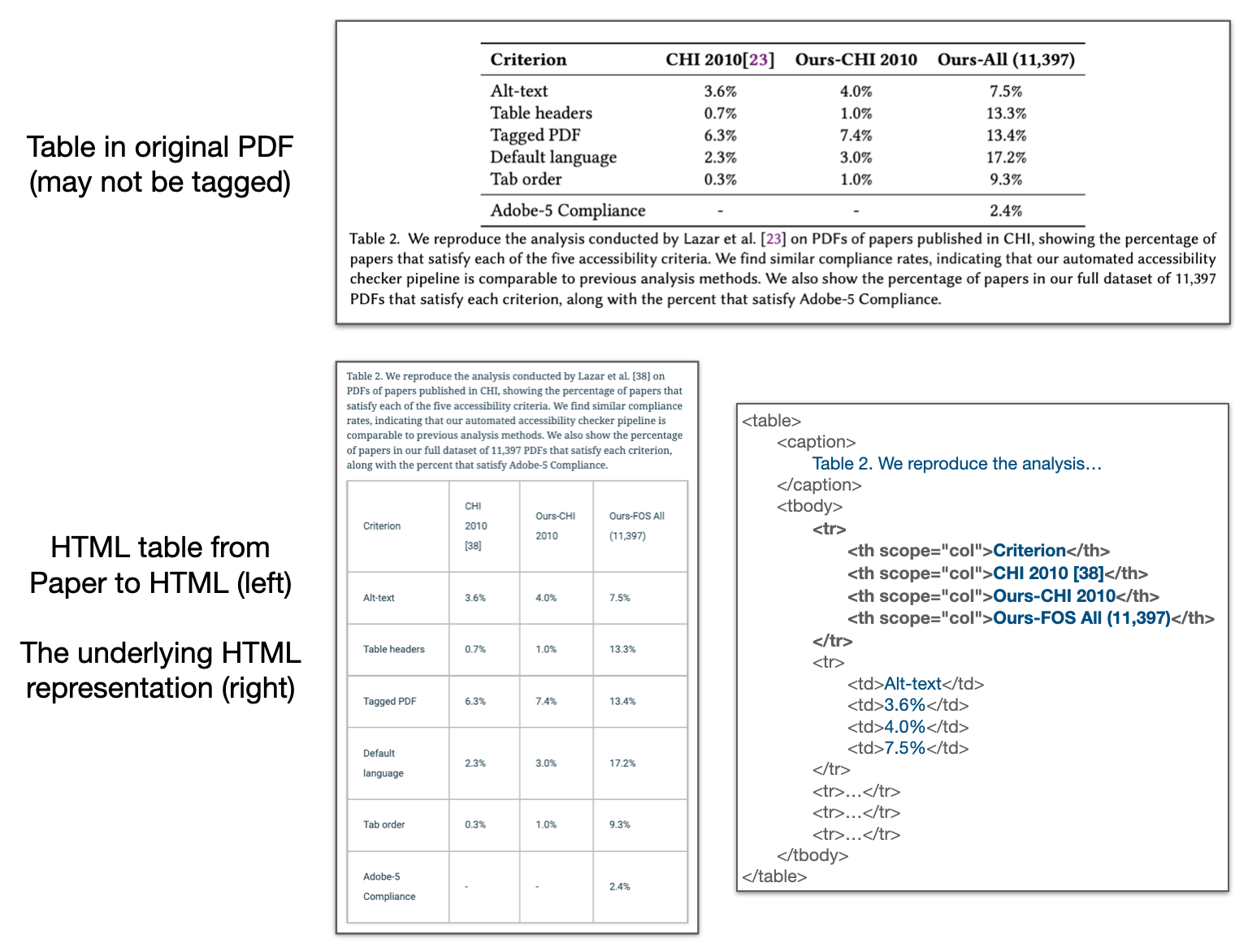
From the formative study we conducted with blind and low vision researchers prior to creating Paper to HTML, we gained insights into user challenges, coping mechanisms, and desired features for scientific document reading (Wang et al. 2021a). We iterated upon these insights and design feedback to develop the current system. Since the release of Paper to HTML publicly in Fall of 2021, a small but dedicated group of users, consisting mostly of blind and low vision academics and researchers, have collectively converted over 6000 scientific PDFs into HTML using this system. During this field deployment, we collected dozens of feedback messages, and have responded by introducing additional features. For example, our system initially extracted tables as images, which are inaccessible. We integrated the Amazon Textract API to automatically and quickly convert table images in uploaded documents into HTML tables, tagging table headings when appropriate, which allows these tables to be navigated and read using assistive reading technology (example in Figure 1).
To further understand the usefulness of Paper to HTML in practice and evaluate the impact of various system features, we intend to conduct a followup interview study, as well as a broader intrinsic evaluation of the faithfulness of HTML renders to the source documents. The goals of the interview study are to better understand how Paper to HTML is being integrated into existing user workflows, what additional benefit it provides over baselines, and where it fails to address accessibility problems (or possibly introduces new usability issues). The goals of the intrinsic evaluation are to determine the accuracy of our conversion process and summarize high level areas in need of improvement and future development. Beyond these planned studies, we will continue to work with our core group of users to address limitations and improve overall system usability. From the user feedback we have already received, we have identified several broad research directions for improving the system, which we describe below.
More faithful extractions with layout-aware document understanding models
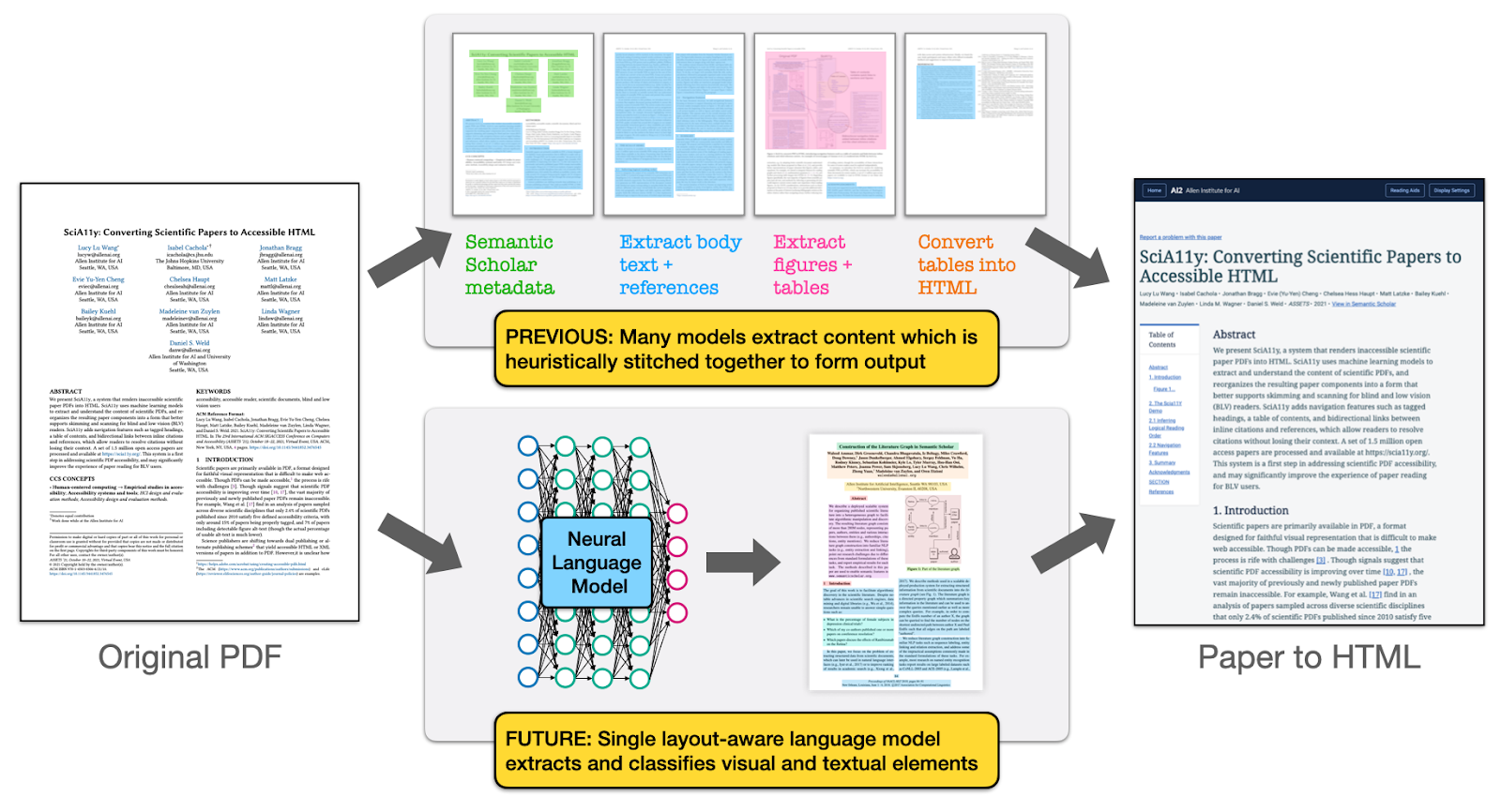
To improve the overall quality of the document parse underlying the Paper to HTML conversion, we have developed document understanding models that leverage visual and textual information to more accurately classify tokens and images within scientific PDF documents (Shen et al. 2022). Building upon sequence-to-sequence models that first linearize tokens from a PDF and classify each token into one of many relevant categories such as paper title, author, abstract, figure, table, body text, equation, and more (Tkaczyk et al. 2014); we aimed to integrate visual information in addition to textual information into these predictions in a more resource-efficient manner than previous layout-aware models (Xu et al. 2020). We introduced a class of Visual Layout (VILA)-aware models that exploit the group uniformity assumption, the observation that tokens within the same visual group on a page tend to have the same category. Models that integrate visual information leveraging this assumption produce more accurate token-level classifications (improving state-of-the-art models by 1-2 points Macro-F1 over 22 classes), and in cases where visual groupings can be used to reduce the total number of classifications, can also significantly reduce inference costs (Shen et al. 2022).
Nonetheless, VILA models are more resource intensive compared to the baseline models we currently use in Paper to HTML, and a significant direction for future work is understanding how to perform on-demand inference cheaply and quickly using these new models. Towards this end, we intend to investigate how model distillation and compression might apply to this class of layout-aware language models, and whether a smaller, more efficient model can be achieved without significant degradation in extraction performance. We hope to replace the current collection of models with a single, higher accuracy, and more efficient layout-aware model that can classify all visual and textual elements in the PDF at once (as in Figure 2).
Towards addressing missing figure alt text
In addition to improving extraction accuracy, we have also been investigating other paper accessibility challenges where AI-based automation does not work well, specifically, the lack of alt text descriptions of image content. Scientific papers are rich in figures and images, which are used to convey results and have been found to be important to blind and low vision readers (Mack et al. 2021). The lack of alt text was also identified as a barrier by all participants in our formative user study. In earlier work (Wang et al. 2021a), we estimated that around 7.5% of PDFs contain alt text, but we have since adjusted this to less than 0.5% upon a more thorough analysis of the identified alt text (Chintalapati et al. 2022). Clearly, this is a major issue affecting the vast majority of scientific PDFs.
There are many possible ways to tackle this challenge, for example, one can develop tools to help authors write more and better alt text, extract relevant information about figures from the paper text, or generate descriptions of figures (semi-)automatically. However, there are few realistic data resources available to study this problem in the scientific domain.
To fill this gap, we collected and released a dataset of author-written alt texts from scientific publications (Chintalapati et al. 2022), which we intend to use to (1) develop tools that support authors to write better alt text and (2) conduct evaluation for automated alt text generation models. Unsurprisingly, the only research community we found with a reasonable level of alt text coverage in its publications was Human-Computer Interaction, where awareness and policy have induced higher compliance with web accessibility guidelines. After extracting over 3000 author-written alt texts from a sample of HCI papers published in the last decade, we annotated a fraction of these (around 500 that corresponded to graphs and charts) for the semantic content included in their alt text using the framework introduced by Lundgard & Satyanarayan 2021. We trained a classifier for identifying semantic levels based on these annotations, which could be used to provide feedback to authors when writing alt texts. These reference alt texts can also be used as a small but realistic evaluation dataset for studying both human-in-the-loop and fully automated figure alt text generation.
Conclusion
Scientific document accessibility remains a major challenge for blind and low vision researchers, students, and workers in STEM industries. Though machine learning solutions for document understanding are imperfect, they can be deployed at-scale or on-demand to any available document, lessening barriers to access. We believe the accuracy of these systems will continue to improve as we develop new advancements in AI and machine learning.
We do not claim that Paper to HTML or any other such automated solution solves all (or even most) accessibility challenges for blind and low vision researchers, but it can smooth these barriers in certain contexts. In addition to fully automated conversion, there is also an opportunity for document understanding systems to accelerate the remediation process and allow the same resources to support more researchers and requests. As one participant in our user study describes: “if papers were more accessible, there would be more blind researchers.” It is our hope that we and others in this community will build upon our findings and continue to lay the groundwork towards reaching this goal.
References
- [Bigham et al. 2016] Bigham, J.P., Brady, E.L., Gleason, C., Guo, A., & Shamma, D.A. (2016). An Uninteresting Tour Through Why Our Research Papers Aren't Accessible. Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems.
- [Chintalapati et al. 2022] Chintalapati, S.S., Bragg, J., & Wang, L.L. (2022). A Dataset of Alt Texts from HCI Publications: Analyses and Uses Towards Producing More Descriptive Alt Texts of Data Visualizations in Scientific Papers. The 24th International ACM SIGACCESS Conference on Computers and Accessibility.
- [Lundgard & Satyanarayan 2021] Lundgard, A., & Satyanarayan, A. (2021). Accessible Visualization via Natural Language Descriptions: A Four-Level Model of Semantic Content. IEEE Transactions on Visualization and Computer Graphics, PP, 1-1.
- [Mack et al. 2021] Mack, K.M., Cutrell, E., Lee, B., & Morris, M.R. (2021). Designing Tools for High-Quality Alt Text Authoring. The 23rd International ACM SIGACCESS Conference on Computers and Accessibility.
- [Shen et al. 2022] Shen, Z., Lo, K., Wang, L.L., Kuehl, B., Weld, D.S., & Downey, D. (2022). VILA: Improving Structured Content Extraction from Scientific PDFs Using Visual Layout Groups. Transactions of the Association for Computational Linguistics, 10, 376-392.
- [Tkaczyk et al. 2014] Tkaczyk, D., Szostek, P., & Bolikowski, L. (2014). GROTOAP2 - The Methodology of Creating a Large Ground Truth Dataset of Scientific Articles. D Lib Mag., 20.
- [Wang et al. 2021a] Wang, L.L., Cachola, I., Bragg, J., Cheng, E., Haupt, C.H., Latzke, M., Kuehl, B., van Zuylen, M., Wagner, L.M., & Weld, D.S. (2021). Improving the Accessibility of Scientific Documents: Current State, User Needs, and a System Solution to Enhance Scientific PDF Accessibility for Blind and Low Vision Users. ArXiv, abs/2105.00076.
- [Wang et al. 2021b] Wang, L.L., Cachola, I., Bragg, J., Cheng, E., Haupt, C.H., Latzke, M., Kuehl, B., van Zuylen, M., Wagner, L.M., & Weld, D.S. (2021). SciA11y: Converting Scientific Papers to Accessible HTML. The 23rd International ACM SIGACCESS Conference on Computers and Accessibility.
- [Xu et al. 2020] Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., & Zhou, M. (2020). LayoutLM: Pre-training of Text and Layout for Document Image Understanding. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.
About the Authors

Lucy Lu Wang is Assistant Professor at the University of Washington Information School and Visiting Scientist at the Allen Institute for AI. Lucy’s research interests include natural language processing, health informatics, document understanding and accessibility, and science of science. Her work on supplement interaction detection, gender trends in academic publishing, and COVID-19 data has been featured in publications such as Geekwire, Axios, VentureBeat, and the New York Times.

Jonathan Bragg is a Senior Research Scientist at the Allen Institute for AI on the Semantic Scholar Research team. Jonathan’s research focuses on AI and Human-Computer Interaction, and he designs, builds, and studies systems that support knowledge work, such as helping people train and evaluate AI models, and helping scientists discover and read scientific literature.

Daniel S. Weld is General Manager & Chief Scientist of Semantic Scholar at the Allen Institute for AI and Professor Emeritus at the Paul G. Allen School of Computer Science & Engineering. Dan was named AAAI Fellow in 1999, deemed ACM Fellow in 2005, and selected to be an AAAS Fellow in 2020. He is a Venture Partner at the Madrona Venture Group and on the Scientific Advisory Boards of Madrona and AI2.