
Design and Evaluation of a Context-Adaptive AAC Application for People with Aphasia
Maurício Vargas, McGill University, mauricio.fontanadevargas@mail.mcgill.caAbstract
Communication with an Alternative and Augmentative Communication (AAC) device tends to be extremely slow, mainly due to difficulties in navigating the extensive vocabulary needed for the generation of spontaneous utterances in a manner that allows the user to easily find and select appropriate words when communicating. This work aims to design, implement, and evaluate a context-adaptive AAC application that suggests the most appropriate words according to the user location and past vocabulary usage.1. Introduction
Picture dictionary-style augmentative and alternative communication (AAC) devices can enhance communication and support the social interactions of people with complex communication needs—including those with aphasia, a communication disorder often acquired later in life—by providing a visual representation of words and phrases and by speaking desired sentences through a synthesized voice. However, communication with an AAC device is extremely slow, typically at rates of 15 words per minute. In contrast, natural speech is around 150 to 250 words per minute, creating an enormous disparity that stunts and delays communication, and hinders interpersonal interactions [2].
The low communication rate of these AAC devices is mainly due to difficulty navigating the vocabulary. Particularly, for those who develop a communication impairment later in life (e.g., people with aphasia), extensive vocabularies are needed to support the generation of complex and nuanced utterances. However, organizing a large vocabulary in a manner that allows the user to quickly and easily find and select appropriate words during spontaneous communication is challenging. Since most users of these devices will have difficulty with written language, alphabetical organization is not possible. Instead, vocabulary items are usually organized in a static hierarchy of categories (e.g. food - breakfast - croissant) that does not reflect common usage and therefore leads to a high number of keystrokes and imposes a high cognitive load during navigation. This work aims to design, implement, and evaluate an AAC application that attempts to suggest relevant vocabulary automatically tailored for the user situation (i.e. context-adaptive), consequently reducing navigation and speeding up communication across a wide range of daily-life situations.
2. Related Work
While adaptation based on context has already been explored in the AAC realm, most research has used contextual information (e.g. location, conversation partner) only for retrieving phrases and words that were manually pre-assigned to specific contexts, and not for generating vocabulary automatically tailored to user’s current needs [8] [10] [12]. Choosing the vocabulary and programming the device imposes extra effort to the user and/or caregivers and may become impractical for those who require a large vocabulary to attend their communication expectations (e.g. adults with acquired disabilities and relatively preserved intellectual abilities, as people with aphasia). In addition, this approach does not scale to unexpected situation or unplanned locations.
Others researchers ([4],[9],[13]) explored the use of statistical language models reflecting vocabulary usage patterns in different location or conversation topics. Using these models, a prediction mechanism suggests the most context-relevant words during message construction. The major drawback in this approach is that its efficacy highly depends on the quality of the language corpora used for training the model, and large corpora representative of AAC communication are still unavailable—dictionaries, websites [4], and small sample of recorded conversations [13] are examples of corpora commonly used.
To provide context-tailored vocabulary without the need of a large and adequate communication corpus collected in advance, some works have explored the use of semantic networks. In such structure, words are linked with each other based on some measure of semantic relatedness, such as evocation rates (i.e. how much a word bring to mind another word) given by online annotators [11] or the number of links between words in WordNET [14] (a lexical database that organizes words in sets of synonyms). Prediction is accomplished by selecting the words most strongly related to the words in the message being composed. The main limitation of these works is that their semantic networks are very sparse or use measures for semantic relatedness that do not reflect words used together in a situation, but rather how similar they are.
Semantic networks have also been explored by psycholinguistic researchers for constructing a model of the human mental lexicon based on the spreading-activation theory [3]. In this theory, when a concept is accessed in our mental lexicon, strongly related concepts are also activated, facilitating their subsequent retrieval. This allows the construction of semantic networks mapping the mental lexicon through word association experiments, in which participants respond to a stimulus word with the first words that come to mind. However, such models have not yet been explored in the context of AAC design.
3. Proposed Methodology
We hypothesize that a relevant, context-tailored vocabulary can be inferred from a semantic network constructed from the largest word association experiment to date (SWOW [5]). This hypothesis is supported by evidence from psychology and networks research on word association data showing that a) most responses are on the same level of detail (coordinates) or involved words likely to appear together in speech (collocates) [1]; b) when analysing responses based on their semantic properties, the majority type of responses is situation-related (e.g. pick - strawberry ; candle - church) [6]; c) applying network clustering to word association data reveals widespread thematic structure in the mental lexicon, with words in a cluster often used in a same situation rather than a taxonomic structure [7]. As an example, one possible cluster in the SWOW data includes morning, delicious, food, bread, drink, eating, juice, and cereal-vocabulary commonly used during breakfast.
3.1. AAC Application Design
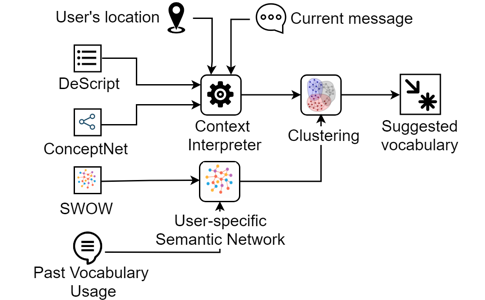
The proposed application is composed of three main components, as illustrated in Figure 1: 1) a user-specific semantic network, built from SWOW data and dynamically updated based on the user’s vocabulary usage; 2) the Context Interpreter, responsible for inferring concepts strongly related with user’s current context based on the geographical location and the message being composed using a commonsense knowledge database (ConceptNET [15]) and annotated scripts of daily-life situations (DeScript [16]); 3) a clustering algorithm that identifies thematic clusters in the semantic network and select the most relevant—based on the concepts delivered by the Context Interpreter—as source of vocabulary to be suggested to the user.
The main challenges in this stage are selecting appropriate relations in ConceptNet and building the algorithm that will merge the commonsense knowledge with the data from the scripts to provide a representation of the user context. Without an accurate representation, the cluster algorithm will not be able to select the cluster(s) containing words relevant to the user’s situation. For example, the concepts order and restaurant are good candidates to represent the context “in a cafeteria”. However, if the concept order is overestimated, the clustering algorithm may suggest words such as law, court, chaos, and clean instead of menu, waiter, and food.
3.2. AAC Application Evaluation
The evaluation objective is to obtain quantitative and qualitative evidence demonstrating the differences in communication performance, ease of use, and user perceptions when communicating under two conditions: a) using a widely used vocabulary designed for people with aphasia (hierarchically-organized into common categories) and b) using the same vocabulary augmented with context-tailored suggestions provided by the proposed application.
The main study will consist of controlled experiments (possibly held at a local association for people with aphasia) where participants will be presented with situations (e.g. having breakfast in a cafeteria), depicted with images and videos, and required to fill in dialogues happening in those situations with words they judge to be the best fit. These dialogues represent both interactions that are likely to happen in those situations and out-of-context conversations, such as asking about one’s outfit during the breakfast. Performance metrics (number of keystrokes, time spent, number of words) will be automatically logged from the device and after each session a semi-structured interview will be conducted to investigate participants’ perceptions during the tasks.
A second study will be conducted using the cognitive walkthrough method to obtain the optimum performance metrics when finding the same words selected by the main study participants. By comparing the data from the two studies, it will be possible to understand variations in performance across tasks and to analyse the learnability of the proposed application.
4. Conclusion
The main contribution of this work relies on the suggestion of vocabulary adapted to both the needs related with user location and the user-specific communication patterns. In contrast of previous works, this approach will not require pre-selection of vocabulary judged to be important and its manual organization into categories representing a limited set of contexts.
The doctoral candidate is in the second year of the study program and is mostly hoping to receive feedback on the evaluation stage, which is an initial idea and needs to be refined.
Acknowledgments
We gratefully acknowledge the funding provided by Fonds de Recherche du Québec - Nature et Technologies (FRQNT) and Age-Well NCE.References
- Jean Aitchison. 2012. Words in the mind : an introduction to the mental lexicon. Wiley-Blackwell.
- David Beukelman and Pat Mirenda. 2005. Augmentative and alternative communication: Supporting children and adults with complex communication needs. Paul H. Brookes Publishing Co.
- Allan M. Collins and Elizabeth F. Loftus. 1975. A spreading-activation theory of semantic processing. Psychological Review 82, 6: 407–428. https://doi.org/10.1037/0033-295X.82.6.407
- Carrie Demmans Epp, Justin Djordjevic, Shimu Wu, Karyn Moffatt, and Ronald M Baecker. 2012. Towards providing just-in-time vocabulary support for assistive and augmentative communication. In Proceedings of the 2012 {ACM} international conference on {Intelligent} {User} {Interfaces}, 33–36. Retrieved November 30, 2014 from http://dl.acm.org/citation.cfm?id=2166973
- Simon De Deyne, Danielle J Navarro, Amy Perfors, Marc Brysbaert, and Gert Storms. 2018. Measuring the associative structure of English: The “Small World of Words” norms for word association. Retrieved from http://compcogscisydney.org/publications/DeDeyneNPBS_swow.pdf . Manuscript submitted for publication.
- Simon De Deyne and Gert Storms. 2008. Word associations: Network and semantic properties. Behavior Research Methods 40, 1: 213–231. https://doi.org/10.3758/BRM.40.1.213
- Simon De Deyne, Steven Verheyen, Amy Perfors, and Daniel J Navarro. 2015. Evidence for widespread thematic structure in the mental lexicon. Cognitive Science Society Proceedings: 518–523.
- Carrie Demmans Epp, Rachelle Campigotto, Alexander Levy, and Ron Baecker. 2011. {MarcoPolo}: context-sensitive mobile communication support. Proc. FICCDAT: RESNA/ICTA. Retrieved December 4, 2014 from http://resna.org/conference/proceedings/2011/RESNA_ICTA/demmans epp-69532.pdf
- Luís Filipe Garcia, Luís Caldas De Oliveira, and David Martins De Matos. 2015. Measuring the Performance of a Location-Aware Text Prediction System. ACM Transactions on Accessible Computing 7, 1: 1–29. https://doi.org/10.1145/2739998
- Shaun K Kane, Barbara Linam-Church, Kyle Althoff, and Denise McCall. 2012. What we talk about: designing a context-aware communication tool for people with aphasia. In Proceedings of the 14th international {ACM} {SIGACCESS} conference on {Computers} and accessibility, 49–56. Retrieved November 9, 2014 from http://dl.acm.org/citation.cfm?id=2384926
- Sonya Nikolova, Marilyn Tremaine, and Perry R Cook. 2010. Click on bake to get cookies: guiding word-finding with semantic associations. In Proceedings of the 12th international {ACM} {SIGACCESS} conference on {Computers} and accessibility, 155–162. Retrieved February 9, 2015 from http://dl.acm.org/citation.cfm?id=1878832
- DongGyu G. Park, Sejun Song, and DoHoon H. Lee. 2014. Smart phone-based context-aware augmentative and alternative communications system. Journal of Central South University 21, 9: 3551–3558. https://doi.org/10.1007/s11771-014-2335-3
- Rupal Patel and Rajiv Radhakrishnan. 2007. Enhancing Access to Situational Vocabulary by Leveraging Geographic Context. Assistive Technology Outcomes and Benefits 4, 1: 99–114.
- Computer Science, Deb K Roy, Thesis Supervisor, and Arthur C Smith. 2002. A Communication Aid with Context-Aware Vocabulary Prediction Ewa Dominowska.
- Robert Speer, Joshua Chin, and Catherine Havasi. 2016. ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. Singh 2002. Retrieved from http://arxiv.org/abs/1612.03975
- Lilian D A Wanzare, Alessandra Zarcone, Stefan Thater, and Manfred Pinkal. 2016. DeScript: A Crowdsourced Corpus for the Acquisition of High-Quality Script Knowledge. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016): 3494–3501.
About the Author

Mauricio is a PhD candidate in the School of Information Studies at McGill University. His doctoral research focuses on improving the usability of Augmentative and Alternative Communication (AAC) devices for people with aphasia and he has also worked on a haptic interface for transmitting words through the skin. Before joining McGill, Mauricio completed his Master’s in Electrical Engineering at Federal University of Rio Grande do Sul, Brazil, where he worked on a service personalization system for smart homes.